A Game Changer: Protein Clustering Powered by Supercomputers
New algorithm lets biologists harness massively parallel supercomputers to make sense of a “data deluge.”
The Science
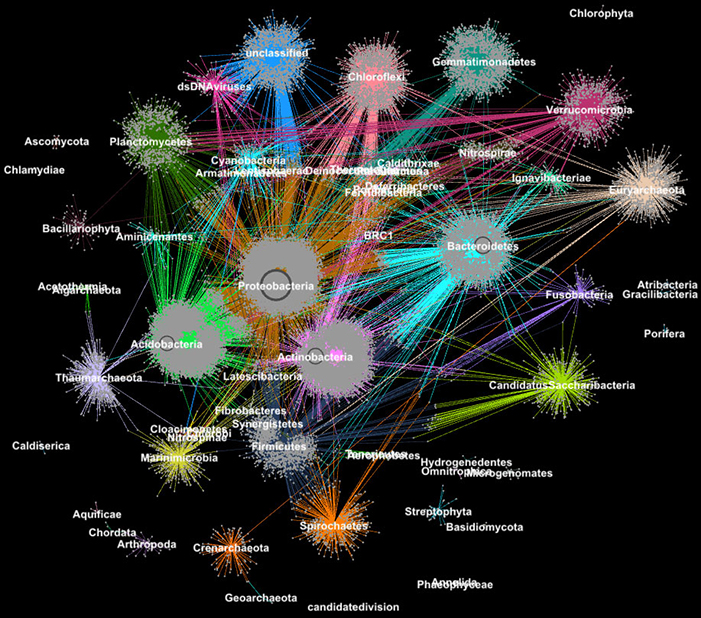
In the world of big data, biologists create data sets containing hundreds of millions of proteins and other cellular components. They apply clustering algorithms to the datasets to identify key patterns. Many of the techniques have been widely used for more than a decade. But they can’t keep up with the torrent of biological data. In fact, few clustering algorithms can handle a biological network with millions of nodes (proteins) and edges (connections). Researchers from Lawrence Berkeley National Laboratory and the Joint Genome Institute took on one of the most popular clustering approaches in modern biology—the Markov Clustering (MCL) algorithm. They modified it to run quickly, efficiently, and at scale on distributed memory supercomputers.
The Impact
The team’s high-performance algorithm—called HipMCL—handles massive biological networks. These networks were impossible to cluster with MCL. With HipMCL, biologists can identify and characterize novel aspects of microbial communities. It works without sacrificing the sensitivity or accuracy of MCL. Using HipMCL, scientists processed a network with about 70 million nodes and 68 billion edges in a few hours. To do this, HipMCL used about 140,000 processor cores at the National Energy Research Scientific Computing Center. As an added benefit, HipMCL runs seamlessly on any computing system.
Summary
Given an arbitrary graph or network, it is difficult to know the most efficient way to visit all of the nodes and links. A random walk gets a sense of the footprint by exploring the entire graph randomly; it starts at a node and moves arbitrarily along an edge to a neighboring node. Because there are many different ways of traveling between nodes in a network, this step repeats numerous times. Algorithms such as MCL will continue running this random walk process until there is no longer a significant difference between the iterations. Performing random walks is by far the most computationally and memory intensive step in a cluster analysis. The best way to execute a random walk simultaneously from many nodes of the graph is with sparse matrix-matrix multiplication.
The unprecedented scalability of HipMCL comes from its use of state-of-the-art algorithms for sparse matrix manipulation. Berkeley Lab computer scientists developed some of the most scalable parallel algorithms for GraphBLAS’s sparse matrix-matrix multiplication and modified one of their state-of-the-art algorithms for HipMCL.
Contact
Ariful Azad
Lawrence Berkeley National Laboratory
azad@lbl.gov
Aydin Buluç
Lawrence Berkeley National Laboratory
abuluc@lbl.gov
Nikos Kyrpides
DOE’s Joint Genome Institute and Lawrence Berkeley National Laboratory
nckyrpides@lbl.gov
Funding
Development of HipMCL was primarily supported by the Department of Energy’s (DOE’s) Office of Science via the Exascale Solutions for Microbiome Analysis (ExaBiome) project, which is developing exascale algorithms and software to address current limitations in metagenomics research. The development of the fundamental ideas behind this research was also supported by DOE’s Office of Advanced Scientific Computing Research’s Applied Math Early Career program. The team used resources at the Joint Genome Institute and the National Energy Research Scientific Computing Center, both DOE Office of Science user facilities.
Publications
A. Azad, G.A. Pavlopoulos, C.A. Ouzounis, N.C. Kyrpides, and A. Buluç, “HipMCL: A high-performance parallel implementation of the Markov clustering algorithm for large-scale networks.” Nucleic Acids Research gkx1313 (2018). [DOI: 10.1093/nar/gkx1313]
Related Links
Lawrence Berkeley National Laboratory press release: A Game Changer: Metagenomic Clustering Powered by HPC
Highlight Categories
Performer: DOE Laboratory , SC User Facilities , ASCR User Facilities , NERSC , BER User Facilities , JGI
Additional: Collaborations , NNSA